1. The Structural Failure of Static Thresholds
The gap between modern financial crime and traditional transaction monitoring is no longer incremental but structural. For decades, the industry has relied on a one-size-fits-all approach: rigid thresholds that fail to differentiate between inherently diverse customer profiles. That design carries a hidden assumption: that a single definition of “normal” fits an entire customer base. In a high-velocity digital payments environment where money moves in milliseconds across borders and behavior varies dramatically by entity type, geography, and product, that assumption has reached its breaking point.
The “false positive” crisis, beyond an operational burden, is a diagnostic failure. Rigid, binary rules fail to distinguish between legitimate business scaling and illicit layering because they lack the context of normality. When compliance teams manually triage thousands of alerts generated by arbitrary dollar caps, they are not really monitoring but managing noise. The FATF’s report on new technologies for AML/CFT makes the regulatory direction explicit: data analytics and machine learning can identify and manage risk “more effectively and closer to real time” than static rule sets. To secure the integrity of the 2026 financial ecosystem, compliance architects must orchestrate a shift from rules to intelligence. The increasingly adopted risk-based approach moves away from heuristic, paper-based compliance toward behavioral profiling and unsupervised machine learning detection engines.
2. The Multidimensionality of Normality: Defining Segmentation
To identify an anomaly, a system must first mathematically define “normal.” This requires the technical segmentation of the customer base into granular peer groups. From an engineering perspective, establishing normality is impossible without a robust data normalization pipeline: we must ingest and standardize disparate transactional data formats and payment schemes before any behavioral logic can be applied. Based on ThetaRay frameworks, we segment the population along several primary axes so that the investigation process remains consistent while the thresholds for normality stay dynamic:
- Entity Type (KYC-driven): We distinguish fundamentally between “Individual” and “Business” behavior. As illustrated in Figure 1, the two populations exhibit visibly different behavioral distributions: businesses typically have higher transaction volumes and values. An activity that triggers a critical alert for an individual (e.g., a $50,000 wire) may be entirely routine for a corporate entity.
- Geographic (KYC-driven): Financial behavior is culturally and operationally distinct. Retail customers in cash-heavy economies like Kenya often exhibit high-frequency cash deposits that would be abnormal for retail clients in Madrid, where digital transfers dominate. Global thresholds fail to capture these nuances, making geographic segmentation essential for accurate normality baselines.
- Product Type (data-driven): Different financial products demand specific behavioral baselines. Micro-payment wallets and prepaid cards involve high-frequency, low-value transactions; in a standard retail checking account model, this velocity would trigger a structuring (“smurfing”) alert. Segmented by product, the same volume is correctly recognized as normal usage, significantly reducing false positives.
- Temporal (data-driven): Financial behavior is inherently cyclical. Segmenting by transaction timing (business hours vs. off-peak or nocturnal activity) yields baselines that separate the machine-like signature of automated scripts from human-driven behavior. This differentiates urgent, high-value corporate batch processing from clandestine, off-hours rapid movement of funds, sharply reducing false positives for legitimate B2B activity.

Figure 1: The same transaction, two different stories. A $50,000 wire is a ~3.8σ event against the individual peer-group distribution, yet falls within ±1σ of the business baseline.
These are only a few of the plausible segmentation axes that can be identified and modeled to extract noise and reduce false positives. For rigid thresholds and rules, this multidimensionality creates a combinatorial explosion. With N segmentation dimensions, where dimension i has kᵢ possible segments, and R rules applied across those segments, the total number of rule variations is:
To put numbers behind a simple example: a mid-sized fintech operating across 10 geographies, serving 3 client segments, supporting 4 channels, offering 4 products, with 2 temporal dimensions, 2 client-tenure categories, and only 5 rules yields:
9,600 distinct rule variations from a seemingly modest setup, each requiring design, calibration, testing, deployment, governance, and ongoing maintenance.
This product reaches hundreds or thousands of combinations rapidly. Maintaining static rules at this scale is unsustainable, creating an operational paradox: rule maintenance costs grow exponentially while detection value diminishes. ThetaRay’s unsupervised and semi-supervised ML circumvents the explosion entirely by dynamically computing per-segment normality, replacing rigid manual rule sets with an objective, algorithmic baseline.
3. Deep Dive: The Mathematical Mechanics of Segmentation
With machine learning, we don’t manually predefine a threshold for each segment. Instead, automated pipelines ingest multidimensional data and let the model learn normality dynamically.
To enhance robustness, each AI model utilizes Thetaray’s proprietary algorithms drawn from diverse mathematical domains: graph-based methods, neural networks, diffusion maps, kernel PCA, and other geometric methods. Fusing the scores from these varied algorithms into a single unified metric enables effective anomaly detection, in most cases without external labels distinguishing true from false positives. This property is critical in AML, where labeled ground truth is scarce and lagging: confirmed laundering cases surface only after investigations, filings, or law-enforcement outcomes, often years after the transactions occurred, and the vast majority of illicit flows are never labeled at all. A supervised model trained on such sparse, delayed labels inherits their blind spots; an unsupervised and semi-supervised approach sidesteps that dependency entirely.
By understanding the business operations and the data structure, the system identifies anomalies that deviate from the expected activity of peers with similar characteristics. So how does an AI-based AML system actually incorporate segmentation into its decision? At three distinct stages of the model lifecycle.
3.1 Pre-Training: Feature-Level Segmentation
Machine learning features are designed to capture financial behavior that can be normalized relative to its specific segment, surfacing truly anomalous activity. Consider a “Total Transaction Value” feature for a corporate client versus a retail customer. Applying segment-aware normalization ensures that an absolute transaction value is evaluated against its relevant peer-group distribution. Formally, we standardize the raw transaction value x relative to the statistical properties of its peer segment S:
where μₛ is the mean and σₛ the standard deviation of the feature within segment S. The anomaly is quantified as a distance from the segment mean: a $50,000 transaction might be a 5σ outlier (highly anomalous) against a retail checking distribution, while the same transaction falls within 1σ for a wholesale SME account (see Figure 1). This prevents the model from flagging noisy-but-legitimate corporate behavior as suspicious while sharpening its sensitivity to subtle deviations in retail accounts.
3.2 During Training: Model-Level Segmentation
When segments are distinct enough to warrant different behavioral logic, we pipeline them into specialized models. Rather than forcing a single, monolithic model to internalize both individual and business AML typologies and normalities, we fork the data pipeline after the feature engineering stage and train specialized “expert models”: one optimized for individual AML detection, a parallel one trained for business AML.
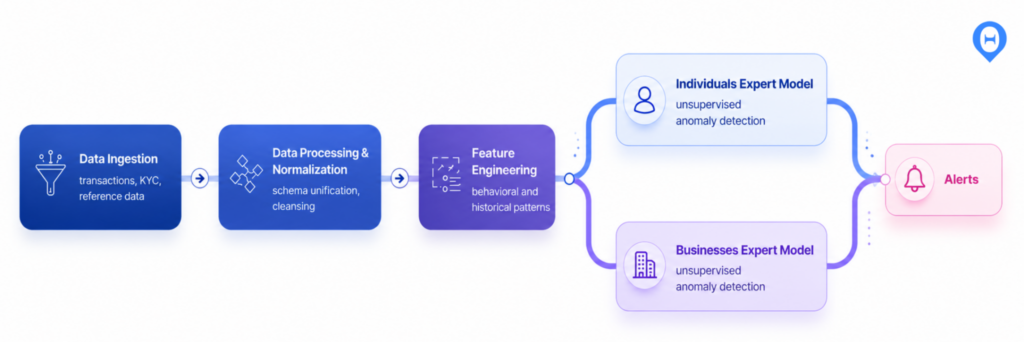
Figure 2: Model-level segmentation. A single shared pipeline forks into per-segment expert models whose outputs converge into a unified alert stream.
Each expert model focuses on the unique “story” of its domain, drastically increasing detection precision and reducing false-positive rates for complex business flows. A subtle but important consequence: predictions for the same input record will differ even when all feature logic is identical across models, because each model’s output is calibrated to the score distribution of the specific segment on which it was trained.
3.3 Post-Training: Risk-Based Threshold Segmentation
Beyond identifying behavioral baselines, AI-based models empower institutions to implement segment-specific risk appetites without retraining the underlying models.
ThetaRay’s AI models output a continuous “fusion” score representing the probability that a record is anomalous. An alert triggers only when this score crosses a decision threshold (τ = 0.5 by default). Rather than a uniform global threshold, we optimize τ per segment risk:
- New-to-Bank customers lack established historical baselines and carry higher inherent risk, so we might lower the threshold to τ = 0.4. This increases sensitivity (recall), capturing potentially illicit behavior even when the anomaly is subtle.
- Established low-risk accounts can maintain τ ≥ 0.5, prioritizing precision and minimizing operational noise.
What would be treated as below-the-line (BTL) for the general population becomes above-the-line (ATL) for the high-risk segment, prompting an investigation.
Compare this with traditional rule-based systems, where accommodating a different risk appetite for a specific demographic requires recalibrating dozens of individual, manual rules, a process prone to error and rule drift. Adjusting the decision threshold in an AI model is an algorithmic calibration of a single risk-tolerance parameter. Because the model provides a holistic, multidimensional view (fusing transactional, static, and behavioral indicators), one threshold shift recalibrates the entire monitoring strategy for that segment: a data-driven, auditable mechanism for managing risk appetite that remains mathematically rigorous and computationally efficient.
4. Takeaways: The Future of Intelligent AML Systems
The objective of a mature AML system is to deliver high-quality, actionable intelligence to law enforcement, not to maximize (or minimize) alert volume. By moving from static thresholds to AI-driven peer grouping and behavioral normality, financial institutions can fulfill the mandates of AML acts and regulations while maintaining operational efficiency.
ThetaRay’s AI-powered AML solution represents a paradigm shift in this endeavor. By mastering the complexities of segmentation and dynamically profiling behavior rather than imposing rigid, static rules, the system dramatically improves the signal-to-noise ratio. It transforms the compliance landscape from a reactive, high-volume alert factory into a proactive, investigation-centric operation. When the model understands what constitutes “normal” within a granular, segment-specific context, false positives are not merely suppressed; they are avoided at the source. That precision lets compliance teams focus their expertise on high-confidence alerts, delivering the actionable, timely intelligence required to combat financial crime in a globalized, digital-first financial ecosystem.
About the Author
